On this page
Know which mutations will work before you spend weeks in the lab.
NeuroAutomata scores every possible amino acid substitution at every position in your protein. Paste a sequence, get a fitness landscape in seconds. Download everything. Your sequences are processed in memory and deleted from our systems within an hour.
What Is NeuroAutomata
NeuroAutomata is a web-based protein mutation scoring tool built on ESM-2, a protein language model developed by Meta AI and trained on millions of protein sequences from across the tree of life. Think of it as a second opinion on your mutagenesis experiments — one that's read every protein sequence in UniProt.
NeuroAutomata now also supports ESMC, a protein language model family released under an open MIT license (commercial use included) by the Chan Zuckerberg Biohub — the nonprofit research institute the original ESM team joined in late 2025. Because it's openly licensed, we can offer it to you directly.
You can choose the model that fits your work:
| Model | Size | Model card | Embedding dim | Runs on |
|---|---|---|---|---|
| ESM-2 650M (default) | 650M | facebook/esm2_t33_650M_UR50D | 1280 | T4 GPU |
| ESMC 600M | 600M | biohub/ESMC-600M | 1152 | T4 GPU |
| ESMC 6B (experimental) | 6B | biohub/ESMC-6B | 2560 | A100 GPU |
You paste a sequence, and NeuroAutomata predicts which mutations are likely tolerable and which ones will probably break your protein. It works on any protein from any organism — even sequences that have never been experimentally characterized — because its predictions come from evolutionary patterns across all known protein families, not from labeled training data specific to your protein.
It runs in your browser. There's nothing to install. Every result you generate — charts and raw scores — is downloadable. Your sequences are processed in memory and deleted from our systems within an hour. Full details in our privacy policy.
NeuroAutomata is built for protein engineers, biochemists, and anyone running mutagenesis on their own proteins. It is free to start, with no card required. Run it on your sequences and tell us what works and what we should fix.
It Already Knew About EGFP
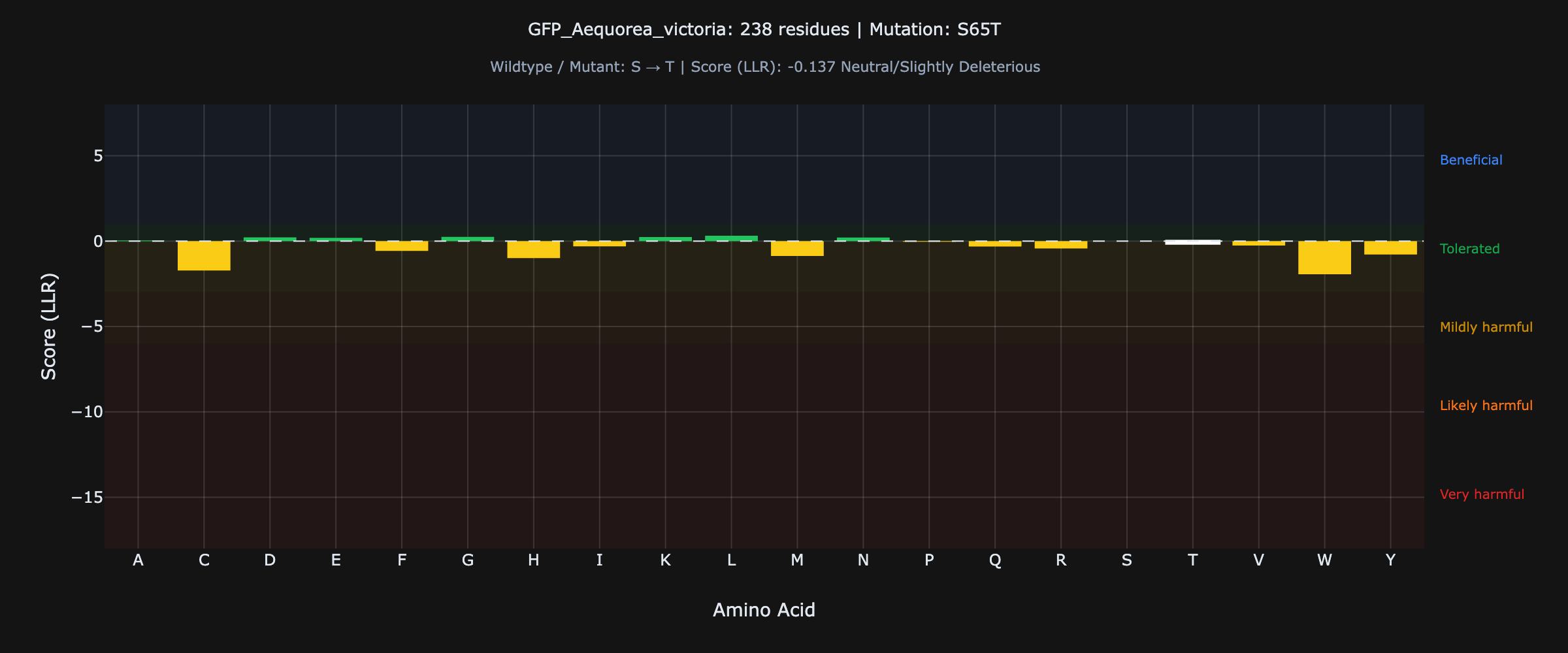
In 1995, Roger Tsien's lab mutated Serine 65 to Threonine in jellyfish GFP and created EGFP — the most widely used fluorescent protein in biology. We ran wild-type GFP (P42212) through NeuroAutomata. In under 30 seconds, it scored S65T as tolerable (-0.137) while flagging S65W and S65C as harmful. It identified the exact mutation that changed biology — without any GFP-specific training data.
See It in Action
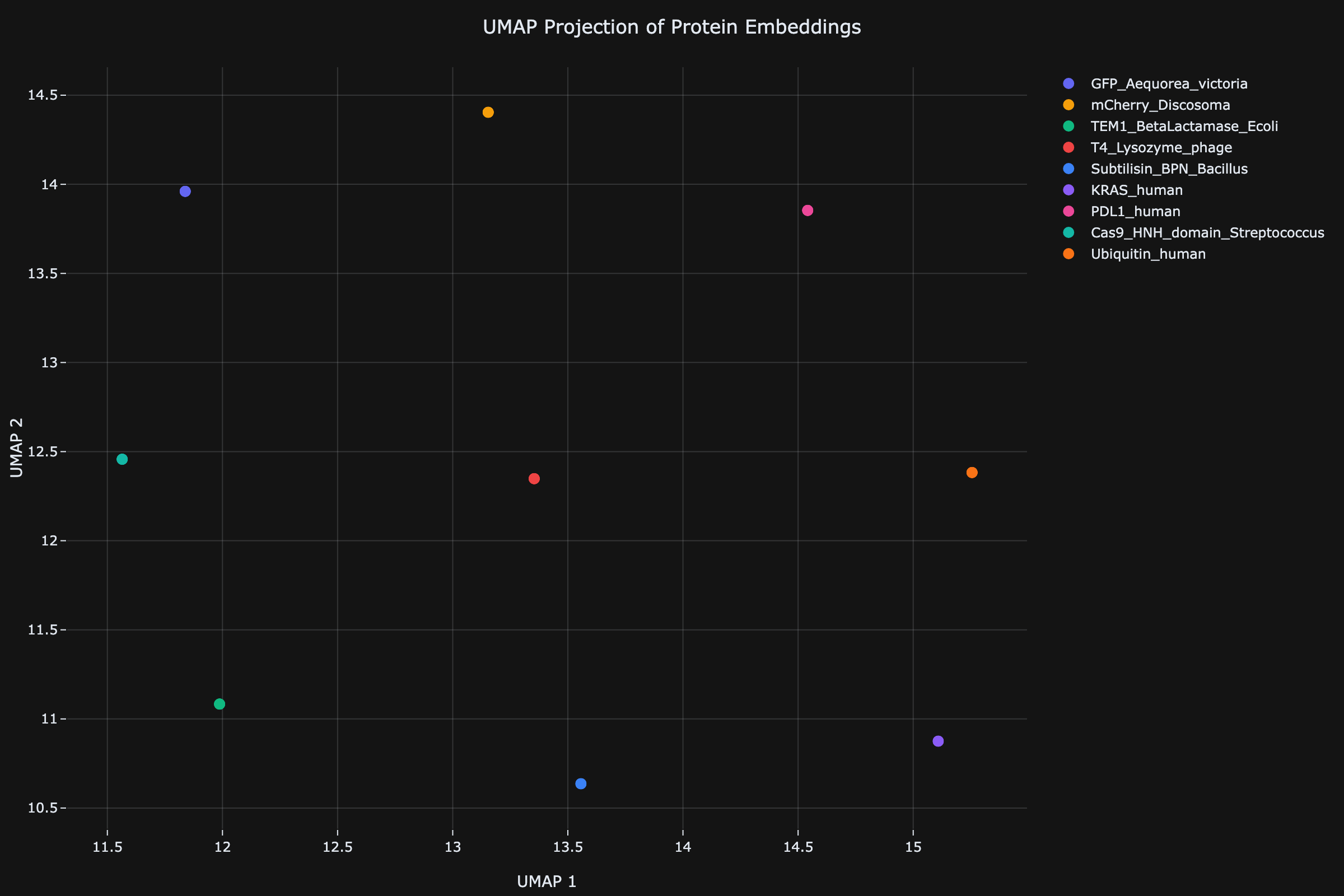
We loaded 9 proteins — fluorescent reporters, therapeutic targets, industrial enzymes, and a CRISPR domain — and scored all of them. Before running any mutations, NeuroAutomata shows you how your proteins relate to each other.
How It Works
Paste your sequence
Amino acid sequence or FASTA format. Up to 1,024 residues. You can also load example proteins to explore first.
Generate a protein fingerprint
The AI model reads your sequence and creates a numerical representation that captures what makes your protein unique — its evolutionary history, structural tendencies, and functional constraints.
Compare your proteins
Load multiple sequences and see which ones are related and which aren't. Proteins with similar functions cluster together — even across organisms.
Score every possible mutation
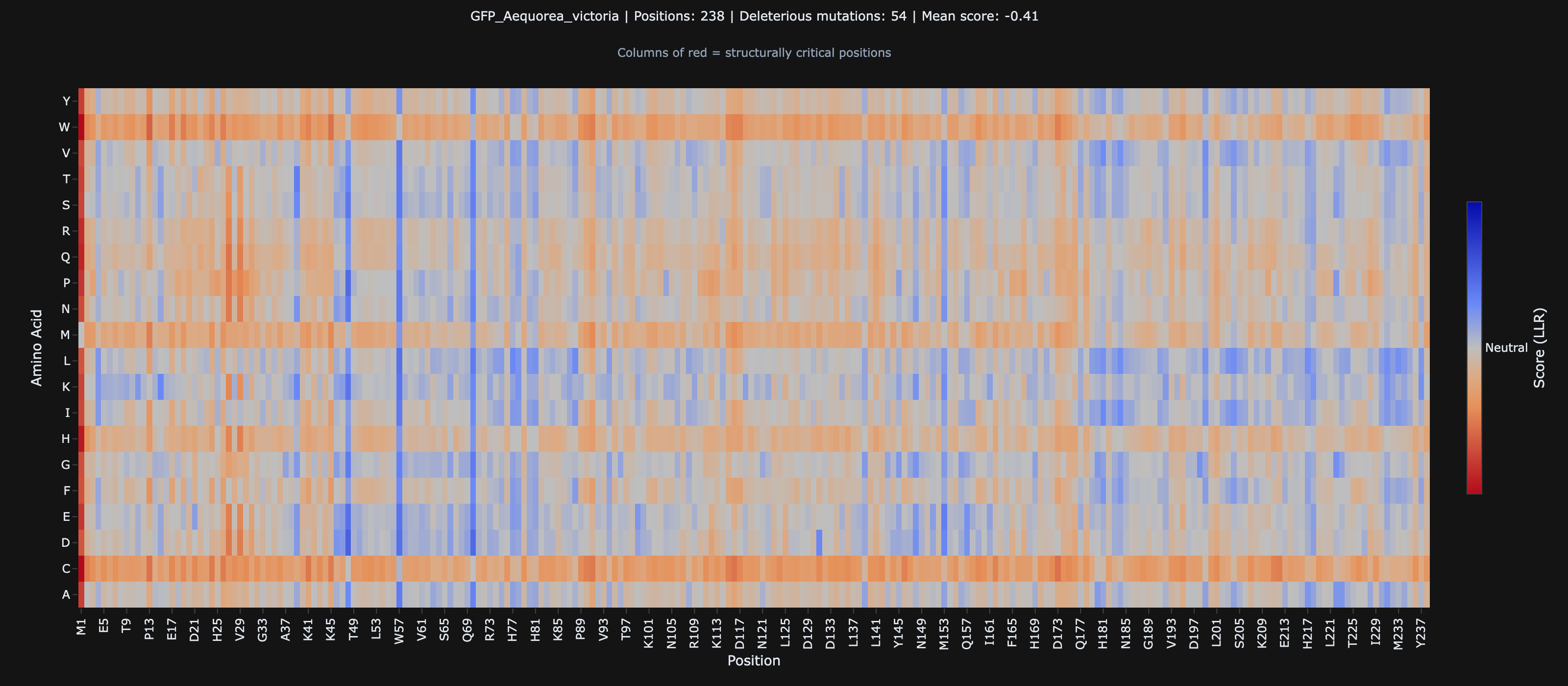
All 20 amino acid substitutions at every position, scored automatically. The heatmap shows you which mutations are tolerated (blue) and which are likely destructive (red) — so you know where to focus before running a single experiment.
See it in 3D
Mutation tolerance scores mapped onto your protein's 3D structure. Blue residues are safe to change. Red residues are conserved. See exactly where your planned mutations sit in physical space.
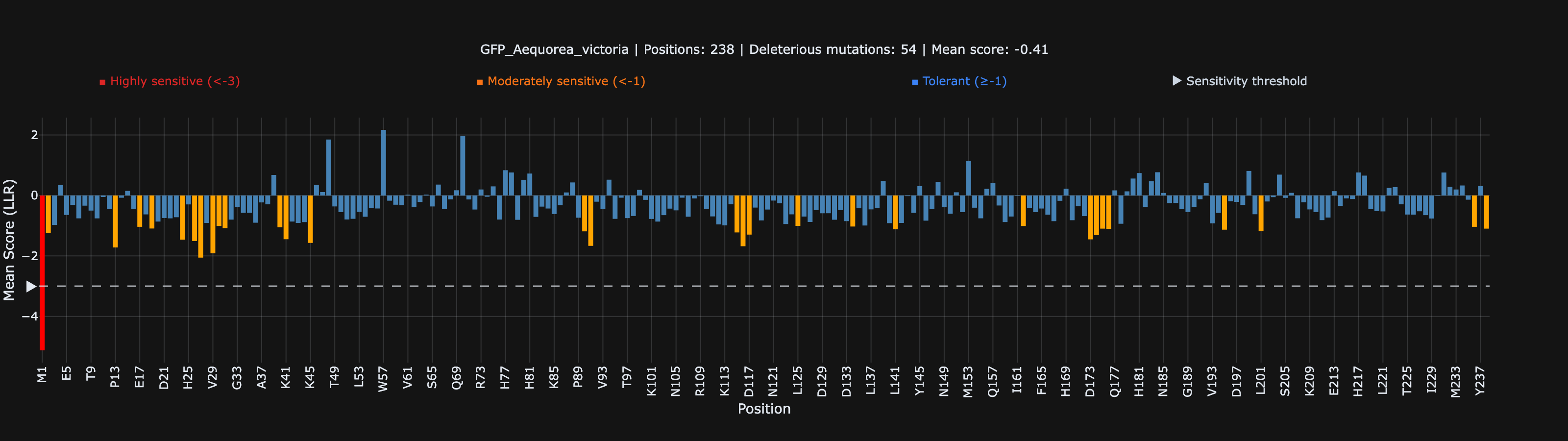
What It Found in GFP
The underlying model was trained on millions of protein sequences from across the tree of life. It learned which positions matter and which are flexible — without being told anything about structure, function, or experimental data. When we scored GFP:
Nobody told the model about the GFP chromophore. Nobody provided GFP-specific training data. It figured this out from sequence patterns alone, in 30 seconds.
Validated Against Real Experiments
We checked NeuroAutomata's predictions against published experimental data: deep mutational scanning results from ProteinGym, a reference benchmark where researchers made the mutations in the lab and measured what each one did. These are clinically and pharmacologically real proteins, not toy examples. They include cancer-associated tumor suppressors, drug-metabolizing and drug-dosing enzymes, and a cell-surface receptor.
| Protein | What the experiment measured | Rank correlation |
|---|---|---|
| Insulin receptor (INSR) | Insulin binding | 0.3989 |
| CYP2C9 | Enzyme activity | 0.679 |
| CYP2C9 | Protein abundance | 0.634 |
| BRCA1 (RING domain) | Gene function | 0.409 |
| BRCA1 (BRCT domain) | Gene function | 0.534 |
| PTEN | Protein abundance | 0.484 |
| TPMT | Protein abundance | 0.5298 |
Across these seven measurements, the median rank correlation is 0.5298. For scale, ESM-2 650M, NeuroAutomata's default model, averages 0.414 across the full ProteinGym benchmark of 217 assays (leaderboard CSV, accessed 2026-05-08). Most of this cohort lands above that benchmark-wide average, though not all of it does.
Where the model is weakest is binding. The two lowest scores are both binding measurements: the insulin receptor at 0.3989, and calmodulin, a calcium-sensing protein we also benchmarked, at 0.212, which is well below the model's own 217-assay average. We report this alongside the strong results rather than burying it. The in-app Learn section walks through the full method: what it does well, and where it falls short.
What Happens to Your Sequences
Your sequences are processed in memory, held in a temporary queue for up to one hour so you can download your results, and then automatically deleted. Nothing is saved to disk. We don't train models on your data. Everything you generate is downloadable, so keep the results you want.
Some processing runs on external services. Running your sequence through the model (embeddings, mutation scoring, and landscape scans) happens on a contracted GPU provider that acts as our data processor. Structure prediction sends your sequence to a separate third-party public API that we don't control. Our privacy policy names each provider and explains how your data is handled.
What You Get
- Works in your browser — nothing to install, nothing to configure
- Results in seconds — not days, not hours
- Works on any protein — from any organism, even ones never studied before
- Download everything you generate — charts and raw data as CSV. Your results, your files.
Use It in Claude and ChatGPT
Run NeuroAutomata where you already work. Add it as a custom connector (currently a beta feature in both assistants) with one URL: works on every Claude plan, and on paid ChatGPT plans with Developer mode turned on. Read the guide →
Plans
NeuroAutomata is open to everyone. Start free, no card required. Upgrade when you need the heavier models and full landscape scans. We are still calibrating what sits where, so plans will keep moving as testers tell us what they need.
Free
Everything you need to start scoring mutations.
- Protein embeddings
- Single-mutation scoring
- Protein comparison and visualization
- Download your results (CSV and chart exports)
Standard throughput
Pro
The full mutation-intelligence workbench.
Everything in Free, plus:
- ESMC-6B embeddings (our largest, experimental model)
- ESMFold structure prediction (PDB structure fetch stays free)
- Full mutation landscape scans (downloadable heatmap across every position)
- Per-residue embeddings
Higher limits and more concurrent jobs
No card required. The free tier stays free.
Plans are in active testing. Limits and the free/pro line may change as we learn how researchers actually use the tool.